
The Rise of AI: From Neural Networks to AGI
What is thinking? What is language? And more importantly, what does it mean to be human? These questions have been thrust upon us with the dawn and ascension of AI. But where did AI come from, how does it work, what potential does it have, and what were the key inflection points in its development? As a University of Bath graduate who has built my own GPT model (here), I'll explore these fascinating questions.
The Birth of Neural Networks
1943 with the Pitts-McCulloch model, which introduced the concept of artificial neural networks inspired by biological brains. These networks aim to solve high-dimensional functions, mimicking the way our brains process information. But what exactly is a neural network?
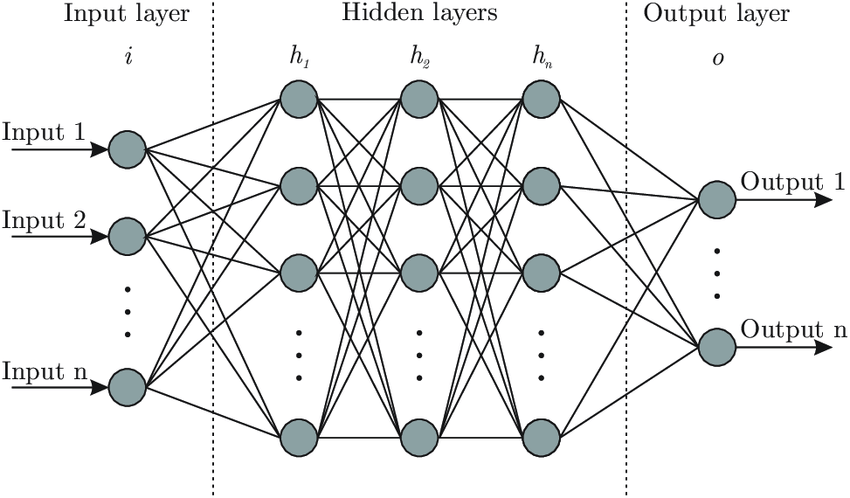
At its core, a neural network is a system of interconnected nodes or "neurons" that process and transmit information. When we study neural networks, we're interested in several key aspects:
- Expressiveness: How well can the network represent complex functions?
- Efficiency: How much data and computing power does it need?
- Architecture: How does the depth (number of hidden layers) vs. width (number of nodes in each hidden layer) of the network affect its performance?
- Scaling laws: How does performance change as we increase the size of the network, training data or compute? Are there phase transitions and why do they occur at those boundries?
- Training dynamics: How do we optimize the network's parameters? (gradient descent)
- Robustness: How well do models generalise, handle outliers and how exploitable are they by adversarial design?
Note: There was many early concerns about neural networks getting stuck in local minima during training but this has largely been debunked in high-dimensional spaces. It was an odd fixation that is continually mentioned in old resources but logically and empirically isn't an issue. every dimention you add makes it expenentially less likely that there exists a local minima as it is unlikely to be a local minima over multiple dimentions and many that may appear such are actually saddle points. This realization opened the door to training much larger and more powerful models.
The Emergence of Word Embeddings: word2vec
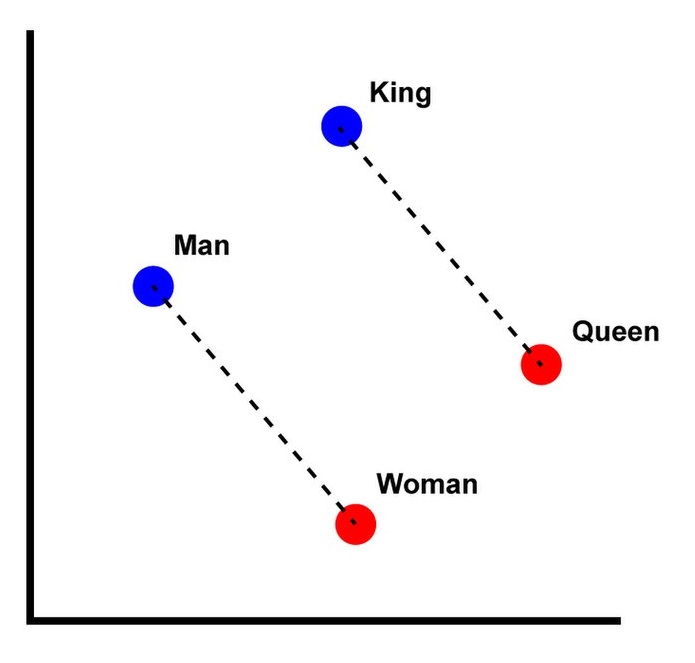
A major breakthrough came in 2013 with the introduction of word embeddings, also known as concept vectors. This approach maps words to points in a high-dimensional space (12,288 dimensions for GPT 3), capturing semantic relationships between words. For some, this idea resonates with Hegel's dialectic, as it represents concepts in relation to each other.
Human communication, despite its complexity, is built upon a surprisingly compact foundation of core concepts. This is evident in how Chinese children can begin reading newspapers after mastering only a few thousand characters, or how simplified languages created during World War II could convey complex ideas using basic terms (e.g., "big cat" for "tiger"). This efficiency suggests our brains operate within a conceptual space of limited dimensions, skillfully combining primitive ideas to construct more intricate thoughts.
The discovery that large language models can effectively represent human language using vector spaces of around 10,000 dimensions aligns with this cognitive efficiency. These models reveal an almost mathematical structure to our thoughts, where concepts combine and transform in ways reminiscent of vector operations. For instance, in this high-dimensional space, "king" - "man" + "woman" often results in a vector close to "queen". (This, while a famous example, is a false one, as the word Queen is also associated with the rock band.) This geometric representation of meaning extends the idea of word embeddings, capturing not just individual concepts, but the complex web of relationships between them, paving the way for more sophisticated language understanding and generation.
However, word embeddings alone weren't enough. We needed a way to handle word order and grammar. This leads us to the next pivotal moment in AI development.
Attention Is All You Need
In 2017, the paper "Attention Is All You Need" introduced the Transformer architecture, revolutionizing natural language processing. The key innovation was the attention mechanism, which allows the model to weigh the importance of different words in a sentence when processing language.
This architecture forms the backbone of modern language models like GPT-3 and GPT-4, released in 2020 and 2023 respectively. These models have shown remarkable capabilities, leading some to question whether they truly "think" – though this quickly becomes a philosophical debate akin to the "No True Scotsman" fallacy.
How Does Attention Work
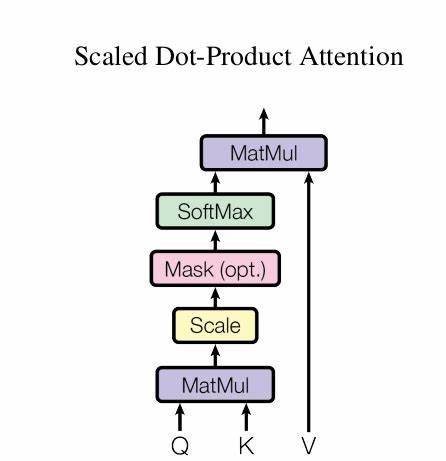
This mechanism revolves around three key components: Queries, Keys, and Values.
Each word in an input sequence is represented by three vectors: a Query vector, a Key vector, and a Value vector. These are created by multiplying the word's embedding with learned weight matrices (Wq, Wk, Wv respectively). The attention mechanism then uses these vectors to determine which words to focus on when processing each word in the sequence.
The process begins by calculating attention scores. This is done by taking the dot product between each Query vector and all Key vectors, resulting in a matrix where each cell represents how much attention one word should pay to another. These scores are then masked to prevent the model from "seeing" future words when predicting the next word in a sequence using a lower triangle matrix.
After applying a softmax function to normalize the scores, we get attention weights. These weights are then used to create a weighted sum of the Value vectors, producing a context-aware representation for each word. This output captures the relationships between words, allowing the model to understand complex language structures.
This elegant mathematical dance allows transformer models to dynamically focus on relevant parts of the input, capturing long-range dependencies and nuanced relationships in text. It's this capability that has made transformers the backbone of state-of-the-art language models
The Challenge of Hallucination
Despite their impressive abilities, large language models face a significant challenge: hallucination. This is when the model generates plausible-sounding but factually incorrect information. Addressing this issue is crucial for practical applications of AI.
One promising approach is the use of focused models with curated knowledge bases. One company have success with this approach is SuperFocus. This technique combines the language understanding of large models with the accuracy of carefully vetted information essentially using two smaller models to prime and verify all information presented comes from the Corpus of correct information. Others are attempting to teach an open-source model directly to determin fact from fiction for itself using synthetic data, finetuning and some built-in chain of thought or multiagent reasoning.
For many practical applications this is the main hurdle, likewise for many specific practical applications this hurdle has been solved already.
The Road to ASI
As we look to the future, the development of Artificial General Intelligence (AGI) looms on the horizon. We're in a period of maximal race conditions, with corporations and nations competing to advance AI technology. This includes:

- Developing domain-specific vs. generalist AI systems
- Improving efficiency and reducing model size
- Creating agentic AI that can interact with external systems
- Incorporating long-term memory, planning, and goal-setting capabilities
While these advancements bring exciting possibilities, they also raise important questions, chiefly what will we all do when AI can do out jobs: better, faster, cheaper, safer and more morally. Multi-Agent frameworks are already out performing low-level experts in nearly every domain from medicine to mathematics. As we move forward, we must grapple with the possibility of AI as a successor species and consider our role in shaping this future.
Conclusion
The development of AI from simple neural networks to potential AGI is a testament to human ingenuity. As we stand at this technological frontier, we must consider not only the capabilities we're creating but also their implications for society and our own identity as humans. The future of AI is being written now, and we all have a part to play in shaping it.
