Motivation: After using large language models like Claude daily, I became curious about their inner workings. To deepen my understanding, I decided to create a small-scale GPT model from scratch.
Objective: Develop a character-level GPT model capable of generating text that resembles English, even if not fully coherent. The primary goal was to achieve correct spelling as a first milestone, with an expected loss of around 1.3 based on initial research. I chose this goal due to my nearly decade old computer limiting my compute.
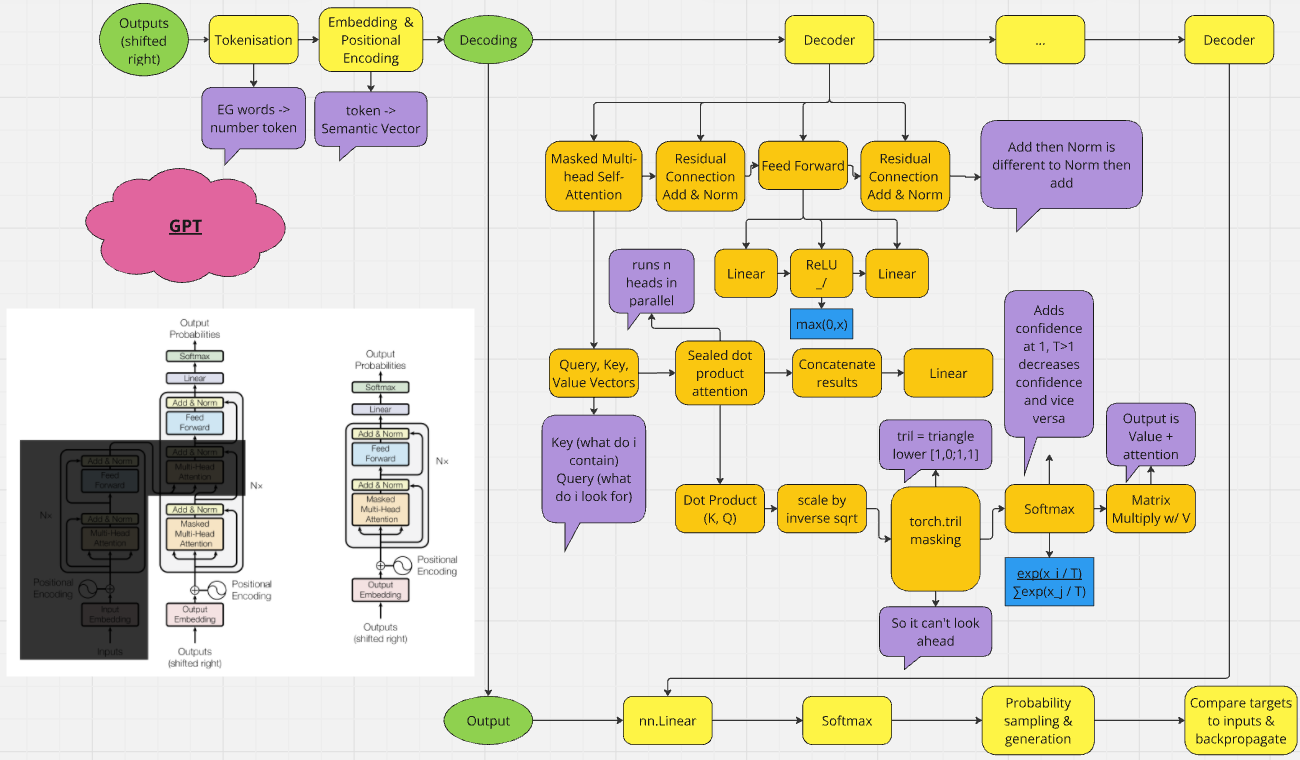
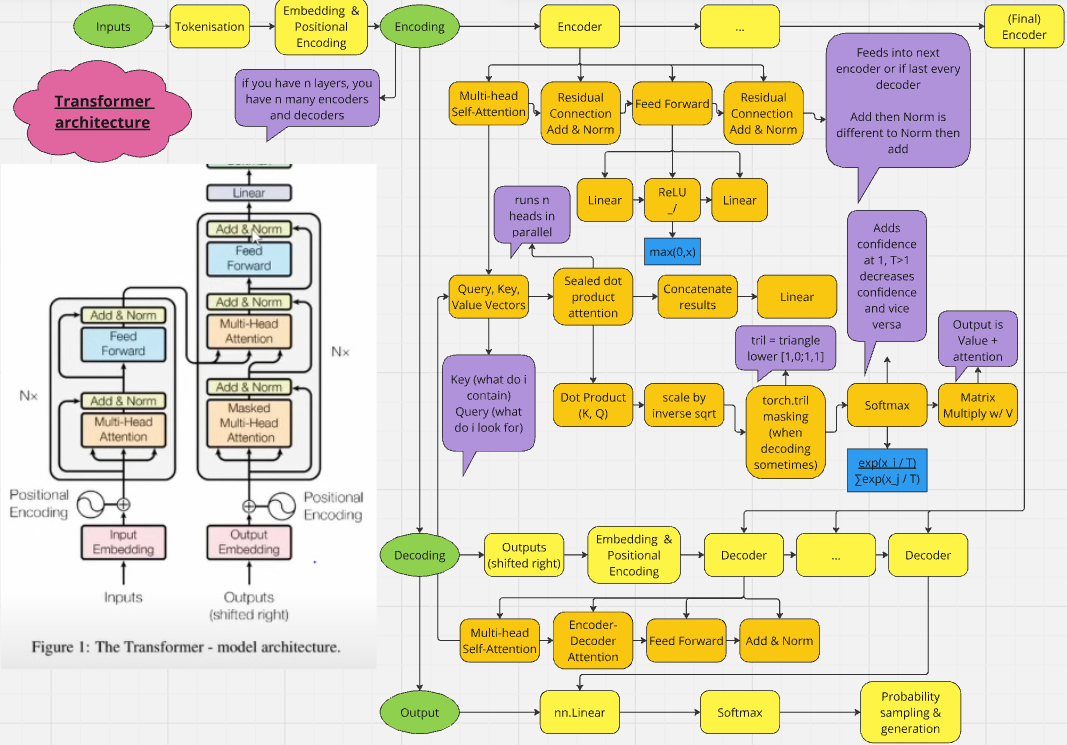
Technical Approach: Implemented a character-level tokenization for computational efficiency. Utilized PyTorch to build the transformer (GPT) architecture. Developed data loading and processing pipelines. Implemented training and evaluation loops. Experimented with hyperparameters to optimize model performance. Created the two diagrams shown during to help with the design.
Key Learnings: Gained hands-on experience with Anaconda, Jupyter Notebook, and argparse. Deepened understanding of the transformer architecture and GPT model. Improved skills in PyTorch usage, code optimisation and efficiency testing. Learned to handle large text datasets efficiently using memory mapping.
Results: Achieved a validation loss of 1.223, surpassing the initial target of 1.3 and demonstrating the model's ability to generate text with correct spelling. Here is some example output with the Prompt "Once upon a time," before and after training.
Impact and Insights: While not intended for practical use, this project provided valuable insights into the workings of language models, the challenges of training them, and the factors contributing to their performance. It significantly enhanced my understanding of NLP and deep learning concepts.
Future Directions: Experiment with different tokenization methods. Implement more automated hyperparameter optimization. Implement fine-tuning techniques. Implement more advanced optimization techniques such as Quantization. Introduce an end token so it can stop on its own. Create a GPT-like model trained solely on synthetic data of Mathematical equations that can easily be checked to see if this architecture is appropriate for a logical math bot. Use a open source LLM for a multi-agent practical application.
Final Thoughts: This project demonstrates my passion for understanding cutting-edge AI technologies and my ability to tackle complex problems through hands-on implementation and experimentation. You can see all the files less than 25mb here.
